背景 在一次线上问题排查中,发现 uWSGI 在某些情况下,会出现假僵尸进程的现象。
问题描述 服务部署很简单,常规的 Django + uWSGI 模式。
uWSGI 配置如下:
1 2 3 4 5 6 [uwsgi] http = :8888 processes = 8 threads = 1 master = true lazy-apps = true
在 uWSGI 的访问日志中,会夹杂一些 500 的响应,但 500 并不是因为 Django 应用代码报错产生的。
而是:
1 2 --- no python application found, check your startup logs for errors --- [pid: 1139 |app: -1 |req: -1 /720133 ] 10.1 .0 .1 () {54 vars in 1184 bytes } [Tue Nov 16 13 :47 :19 2021 ] POST /api/v1/test => generated 21 bytes in 0 msecs (HTTP/1.0 500 ) 2 headers in 83 bytes (0 switches on core 0 )
然后经过日志分析,发现 500 的请求都是由 uWSGI 的某两个固定子进程所处理的。
uWSGI服务一共启动了8个子进程,其中有两个子进程出现了问题,导致服务接口有 1/4的概率调用失败。
那么问题来了。
为什么会出现两个,而不是全部都有问题?
看现象是 uWSGI 的子进程的问题,为什么 uWSGI 没有自动处理这些有问题的子进程?
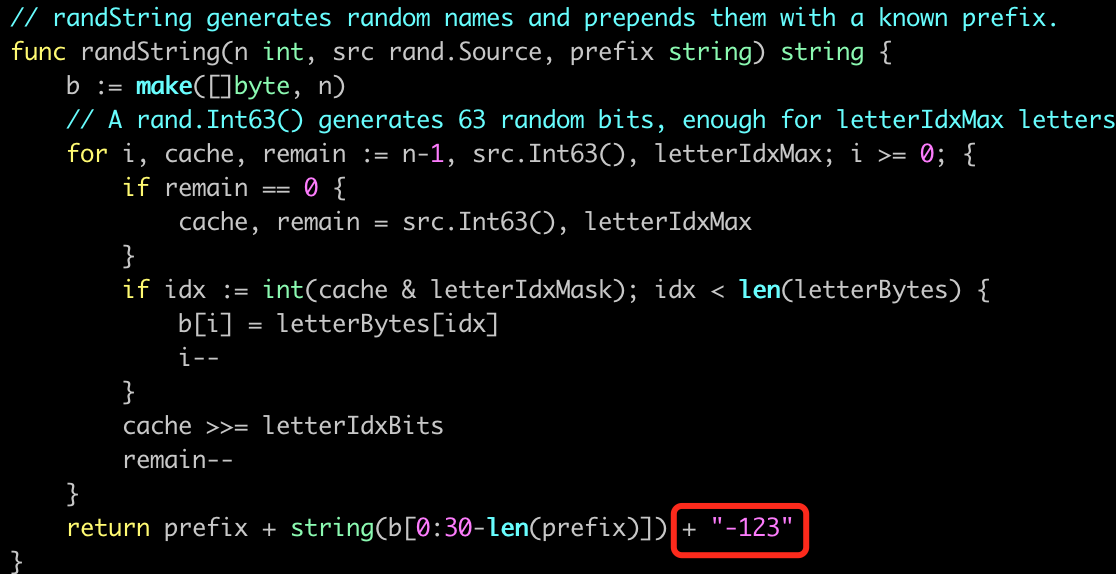
原因分析 针对第一个问题,经过日志分析,定位到在 500 响应第一次出现的时间点里,发生过内存不够的现象,
某个请求内存不够导致了其所在 worker 的重启,但重启的时候内存还是不太够,虽然 worker 进程启
动成功,但在加载 Django 应用代码的时候加载失败。如下图
此时就出现了,某些 worker 正常, 某些 worker 异常的情况。
针对第二个问题,就需要去了解一下 uWSGI 的运行机制了。首先看一下在 worker 启动的时候,uWSGI 会做什么。
以下代码出自 uWSGI 源码:https://github.com/unbit/uwsgi/
一个基本的调用链:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 """ uwsgi_init <= uwsgi.main.c || core/uwsgi.c -> uwsgi_setup <= uwsgi.c -> uwsgi_worker_run -> uwsgi_init_all_apps -> init_apps(uwsgi_python_init_apps) <= plugins/python/python_plugin.c -> init_uwsgi_app <= plugins/python/pyloader.c -> uwsgi_file_loader """
关键代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 wi->callable = up.loaders[loader](arg1); if (!wi->callable) { uwsgi_log ("unable to load app %d (mountpoint='%s') (callable not found or import error)\n" , id, wi->mountpoint); goto doh; } doh: if (PyErr_Occurred ()) PyErr_Print (); return -1 ;
当 uWSGI 尝试加载 python 代码时,如果加载失败,则返回 appid 为 -1 ;
然后:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 if (uwsgi_apps_cnt == 0 && uwsgi.numproc > 0 && !uwsgi.command_mode) { if (uwsgi.need_app) { if (!uwsgi.lazy) uwsgi_log ("*** no app loaded. GAME OVER ***\n" ); if (uwsgi.lazy_apps) { if (uwsgi.master_process) { if (kill (uwsgi.workers[0 ].pid, SIGINT)) { uwsgi_error ("kill()" ); } } } exit (UWSGI_FAILED_APP_CODE); } else { uwsgi_log ("*** no app loaded. going in full dynamic mode ***\n" ); } }
当 worker 加载 app 失败时,会根据配置项决定是直接退出还是进入 dynamic 模式(默认配置)。
所以第二个问题的答案是: uWSGI 不认为这些进程是异常的,因此不作处理。
优化措施 最容易想到的一个优化措施是,在加载 app 失败的时候重试几次,但查了一下 uWSGI 的配置项后,
发现并没有相关选项,其实在分析代码过程中也能看出来,根本没有类似功能的代码。
那么只能从现有选项上着手尝试解决了。
先列一下涉及到的一些配置项:
master: 官方文档强烈推荐开启,但关于此选项的解释又很少
这里简单总结一下,启用 master 模式的话,uwsgi会启动 (1 + 1 + processes)个进程。其中第一个为 uWSGI主进程,第二个为 master 进程,专门用来管理 worker。之后会启动指定数量的 worker 进程。
至于为啥不用主进程来管理 worker, 这个问题我还不是很清楚。
master 进程的好处基本都在这里写完了:https://uwsgi-docs-zh.readthedocs.io/zh_CN/latest/articles/TheArtOfGracefulReloading.html
在 master 模式下,如果 worker 进程被 KILL,那么会自动被 master 进程重启,而非 master 模式则不会,并且 worker 进程会变成僵尸进程。
dynamic-apps: 所谓 dynamic 模式,就是指可以在每一个请求中附加参数来指定处理该请求的 app。
uWSGI 的多个 worker 之间是可以分别加载不同的应用代码的. 参见:https://uwsgi-docs.readthedocs.io/en/latest/DynamicApps.html
lazy-apps: 简单来说就是在 worker 进程启动完成后才开始加载 app 代码,
lazy: 同 lazy-apps,但已废弃,不推荐使用。
need-app: 如果 worker 没有加载到 app, 则直接退出。
max-requests: 设置 worker 处理的最大请求数量, 如果超过最大值则重启 worker.
max-requests-delta: 防止 worker 同时到达最大值而设置的一个差异值,会将每个 worker 的 max-requests 设置为 max-requests + ( worker_id * delta )
min-worker-lifetime: worker 重启的最小间隔描述,默认60
max-worker-lifetime: worker 将会在设置的秒数之后被重启, 默认不启用
max-worker-lifetime-delta: 类似于 max-requests-delta
worker-reload-mercy: worker 在被重启前默认的最大等待时间,worker 可以在这段时间内处理尚未完成的请求.
第一种解决方式:
  暴力一些,设置 need-app 为 true, 这样当加载失败的时候直接退出 uWSGI, 不过这个依赖于服务重启策略,如果采用 docker 部署,可以采用自动重启来保证服务稳定性。
第二种解决方式:
  优雅一些, 设置 max-worker-lifetime, 这样当出现异常 worker 时,不会让异常 worker 一直处于异常的状态。
不同的方式其实适用于不同的场景。
  第一种方式的影响就是在重启期间完全不可用。
  第二种方式的影响是在 worker 异常期间有一定概率服务请求失败。
单纯这么比较的话,貌似第二种稍微好一点,但第一种方式其实有很多办法做到用户完全无感知的。
举个例子:
  在使用 k8s 进行应用部署的时候,将后端服务部署的 Deployment 中 Pod 格式设置为大于1, 并且使用 Service 来访问后端服务,
这样的话,当某个后端 Pod 重启,则完全不会影响服务可用性。
总结一下:没有绝对通用的策略,有的只是根据应用场景设计出来的适合的策略。
思考 uWSGI 为何不提供一种模式来处理随机加载失败的情况呢?
可能的原因是:
1、这个场景很少,没遇到过(概率极低)
2、没有很完美的处理方式,比如很简单的处理方式是加载失败时重试,可设置重试次数,重试间隔等。但这个也无法保证一定可以加载成功。
3、存在其他手段,例如设置 worker 生存时间来处理。
以前所不曾关注到的点 uWSGI 其实并不是一个简单易用的 Web 服务器,参考官方文档的定义:
The best definition for uWSGI is “Swiss Army Knife for your network applications”.
对 uWSGI 的最好形容是网络应用的瑞士军刀,可以应对任何情况,但前提是你得很熟悉它的用法。
uWSGI 并不是为 Python 而开发的,它最开始是在 Perl 语言中使用的, 而且也不叫 uWSGI.
参考 使用 uWSGI 前必读
  https://uwsgi-docs.readthedocs.io/en/latest/Management.html
  https://uwsgi-docs.readthedocs.io/en/latest/FAQ.html?highlight=ProcessManagement#why-should-i-choose-uwsgi
  https://uwsgi-docs-zh.readthedocs.io/zh_CN/latest/articles/TheArtOfGracefulReloading.html
github issue:
  https://github.com/unbit/uwsgi/issues/2374